Imagine spending months refining a machine learning (ML) model only to see it stall before production. You’re not alone. Multiple sources revealed that 87% of machine learning models never make it past the model evaluation phase.
This statistic doesn’t suggest a model’s weakness or a lack of technical know-how. Often, ML models simply don’t meet critical evaluation goals. Within the CRISP-DM framework, model evaluation stands out as a checkpoint to validate performance and ensure that business objectives are met.
In this article, we’ll explore essential evaluation techniques and best practices. We’ll also discuss practical steps for assessing model performance, confirm its reliability, and align it with your specific use case so that it doesn’t become one of the 90% that fail to reach real-world deployment.
Model Evaluation as the Foundation of Reliable AI
Model evaluation in machine learning is the process of testing a model against specific standards and metrics to determine its effectiveness. It can be done in two ways:
- Offline evaluation (before deployment): This involves testing your model on a static dataset. First, you split the data into training and test sets. Then, you build the model on the training set and assess its performance on the test set.
- Online evaluation (after deployment): Real-world data can differ from training data, especially if you expect degradation over time. Testing your model with live and real-time data is key for continuous monitoring.
ML engineers rely on evaluation metrics to confirm that a model meets its objectives. By comparing these metrics against pre-defined goals, they can detect if it has become too specialized in its training data (overfitting), compromising its ability to handle unfamiliar scenarios.
This process ensures the model remains robust and adaptable to new data, aligning it with technical and business requirements. Now, let’s explore key evaluation techniques to help you achieve these goals.
Key Model Evaluation Techniques
So far, we’ve established why evaluation is crucial, but choosing the right metrics is equally essential. In an imbalanced scenario like fraud detection, where fraud makes up less than 1% of transactions, accuracy alone can be misleading. A model always predicting “not fraud” could claim 99% accuracy yet miss all actual fraud cases.
By using the right techniques that reflect the complexity of your data and objectives, you ensure the model remains effective in real-world scenarios. Let’s look at key model evaluation techniques and why they are widely used by ML engineers.
1. Train-test Split and Cross-validation
The train-test split is a foundational method for partitioning your dataset into two parts: train and test. Typically, a larger portion (such as 70% or 80%) is dedicated to training so that the model has sufficient data to learn, while the remaining is reserved for evaluating performance on unseen data. However, a single split may yield a biased performance estimate, especially with small datasets.
To address this, cross-validation systematically divides the data into multiple folds. The model is then trained and evaluated multiple times, with each fold taking turns as the test set. This process provides a more reliable performance estimate and helps detect issues like overfitting or underfitting.
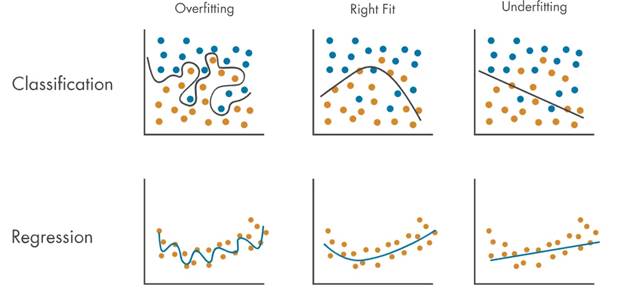
Source: Medium
Overfitting is when a model performs excellently on training data yet fails when presented with unseen data, while underfitting is when it is too simplistic to capture the underlying patterns.
As the need for more robust ML models increases, many companies look for professional AI Data Services in order to guarantee that they have the proper, labeled data to build their models correctly. The availability of adequate and well-prepared data helps avoid overfitting or underfitting, resulting in better and more generalizable models.
2. Model Evaluation Metrics
Evaluation metrics quantify a model’s performance by measuring how well it meets specific objectives. This metric often varies depending on whether the task is classification or regression. They are crucial for understanding overall model effectiveness, identifying potential biases, and ensuring robustness.
Classification Evaluation Metrics
For tasks where the target variable is categorical, a confusion matrix is commonly used. This N x N matrix breaks down predictions into four outcomes:
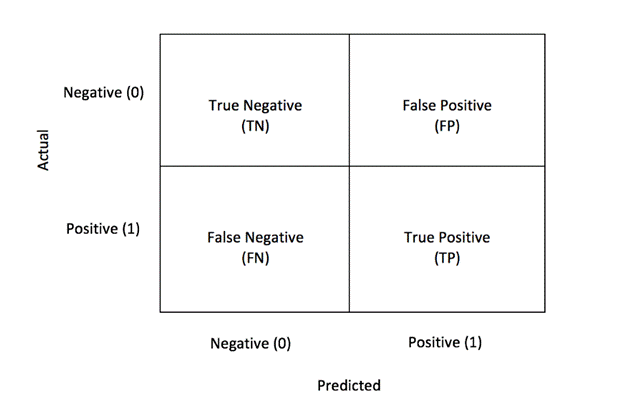
- True Positives (TP): When the positive class is correctly predicted
- True Negatives (TN): When the negative class is correctly predicted
- False Positives (FP): When the positive class is incorrectly predicted
- False Negatives (FN): When the negative class is correctly predicted

Source: Medium
From this confusion matrix, we get key evaluation metrics, such as:
- Accuracy: The measure of the overall correctness of the model.

- Precision: The measure of how many predicted positives were actually positive.

- Recall (Sensitivity): The measure of how many actual positives were identified.

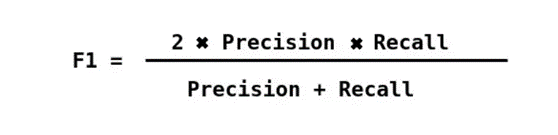
- F1-score: The harmonic mean of precision and recall.
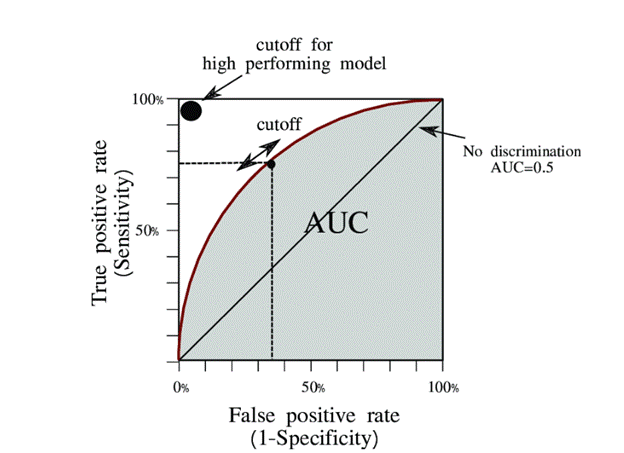
- Receiver Operating Characteristic (ROC) Curve and Area Under the Curve (AUC): This measures how well the classifier distinguishes between classes.
Note: If you have an imbalanced dataset, accuracy alone will be misleading. Focus on Precision, Recall, and F1-score for better assessment.
Regression Evaluation Metrics
Regression models are your go-to when predicting continuous values. They help to quantify how far apart predictions are from actual values, compare different models, and choose the best-performing one. However, regression models are evaluated using different metrics:
- Mean Squared Error (MSE): Measures the average squared difference between predicted and observed outcomes.

Source: suboptimal
- Root Mean Squared Error (RMSE): This is the square root of the MSE, conveying the error magnitude in the same units as the target.
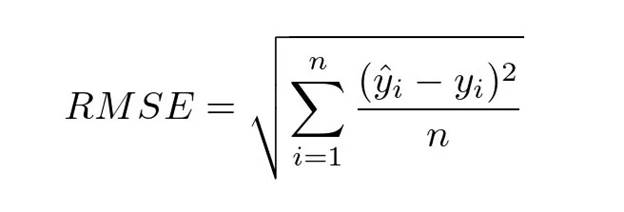
- Mean Absolute Error (MAE): This measures the difference between predicted and observed outcomes.
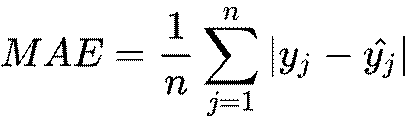
- R-Squared (R²) Score: Indicates how well the model explains the variance in the target variable.
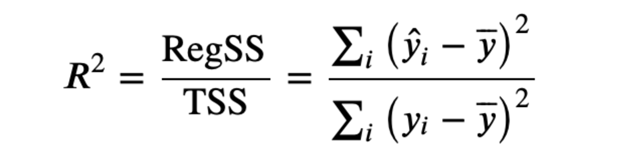
Where:
- RegSS (Regression Sum of Squares) – sum of squared deviations of the predicted values from the mean of the observed values.
- TSS (Total Sum of Squares) – sum of squared deviations of the actual values from their mean.
If you have to use R², consider using it with RMSE. While R² shows how well the predictor explains variance in the data, RMSE highlights the magnitude of its errors.
3. A/B Testing
A/B testing is a real-world evaluation method used after a deployment. By creating two variations of a model and exposing them to live users, you can directly compare their performance. This method validates the model’s performance under real-world conditions, revealing user behavior changes and potential biases that may not have surfaced during development. Pilot programs and controlled experiments thus play a crucial role in ensuring that the model delivers the anticipated business value at scale.
7 Overlooked but Crucial Tips for Model Evaluation
Some of the model evaluation techniques we have discussed are popular among the ML community. However, here are less popular yet crucial tips to remember.
- Business impact metrics are as important as technical metrics. Both should be considered during development, testing, and deployment. For example, reducing false negatives may be more important than accuracy in fraud detection.
- When working with time-series data, ensure that you split according to chronological observations. Don’t split randomly; instead, ensure that training data comes before test data.
- Always check for data leakage or distribution shifts. One way to do that is by using a classifier to check the difference between the test and training data.
- If users can override your model’s predictions in real-world deployment, analyze the rejections to improve the ML system.
- To test how well your model can withstand variations in live data, add synthetic noise or adversarial examples.
- Run models in “shadow mode” parallel to existing decision-making processes to compare their predictions against real-world outcomes without affecting operations. This is best done before deploying the models.
- Backtest with historical data. This is widely done in finance, but many other fields overlook this. For predictive models, you could simulate how they would have performed in past real-world cases.
Building Reliable AI Models with Expert Data Services
AI is the future. It is already gaining momentum now. Building reliable, accurate, and trustworthy AI models is no longer optional; it is now a necessity. Businesses that overlook a thorough evaluation risk costly errors that put lives and revenue at stake.
At EC Innovation, we specialize in AI data services that streamline and enhance data-driven activities across various fields, including finance, gaming IT, medical and pharmaceutical sciences, industrial automation, retail, legal and patent services, online education, autonomous driving, and medical devices. You can contact us today to learn how we can help your business.





